
Self-hosting LLM: Kdy se vám vyplatí
Taky zvažujete, že si budete LLMs hostovat sami? ML inženýr Antonín Hoskovec v této oblasti dlouhodobě experimentuje. Díky jeho článku se budete moct lépe rozhodnout, zda se to vyplatí.
Self-hosting LLM se stává realitou: Jak si stojí menší otevřené modely proti cloudovým gigantům?
Šílená matematika agentů: První systematická studie tokenů odhaluje poměr 154:1 a obří variabilitu v nákladech.
Proč leaderboards lžou: CAISI, METR a UK AISI ukazují reálný „frontier lag“ a modelové podvádění.
Náš test v GSO-bench: Qwen 3.6 27B dorovnal v optimalizaci kódu Gemini 3.1 Pro s polovičním limitem iterací.
🚀 Velký obrat k vlastnímu železu?
Pamatujete na loňský rok? Myšlenka, že by si střední firma provozovala vlastní LLM na vlastní nebo pronajaté infrastruktuře, byla víceméně sci-fi. Bránily tomu tři hlavní překážky:
Nedostupnost hardwaru pro běžné smrtelníky: Sehnat výkonné GPU pro inference velkých modelů vyžadovalo buď upsat duši cloudovým gigantům, nebo mít obří štěstí v hardwarové loterii.
Ekonomická nerentabilita: I když jste překonali technické překážky, průměrné firemní útraty za LLM nebyly tak vysoké, aby ospravedlnily vysoké fixní náklady a správu vlastního železa.
Funkční a kvalitativní propast: Otevřené modely (open-weight) výrazně zaostávaly za uzavřenými (closed-source) nejen v logickém uvažování, ale i ve funkcích. Zpracování obrázků, PDF či pokročilá práce s kontextem byly doménou výhradně placených API.
Dnes je ale situace dramaticky jiná. Jak zaznělo na AI Ascent 2026 od Sequoia Capital, nálada v komunitě se zásadně otáčí. Self-hosting se přesouvá z kategorie „pro nadšence“ do reálných firemních strategií. A tak jsme se v Mitonu rozhodli to vyzkoušet na vlastní kůži – od obřích modelů jako Kimi K2.6 až po spravovatelnější Qwen 3.6 27B.
Podívejme se nejdřív na hardware. Dnes už nemusíte vlastnit serverovnu. Na platformách jako Vast.ai nebo RunPod.io si můžete pronajmout monstra s 8x B200 za rozumných cca $40 za hodinu. Co je ale ještě zajímavější pro běžné firmy: stroje se 4 slušnými GPU a celkovou VRAM kolem 160 GB dnes seženete za pouhé $3 až $4 za hodinu. To je kapacita, která s přehledem stačí na provoz 30B rodiny modelů, a to včetně image enkodérů.
Druhý faktor je růst firemních útrat. Podle analýzy Menlo Ventures 2025: The State of Generative AI in the Enterprise vzrostla průměrná firemní útrata za LLM mezi lety 2024 a 2025 neuvěřitelně 3,2x a rok 2026 neukazuje žádné známky zpomalení. Najednou už neutrácíme stovky dolarů měsíčně za API, ale desetitisíce. A při takových objemech už dává smysl uvažovat o vlastním.
A to jsme ještě nezmínili ty největší výhody self-hostingu: plnou kontrolu nad vaším stackem. Víte přesně, kam vaše citlivá firemní data tečou, nikdo je nepoužívá k trénování, nikdo nezná vaše interní use-casy a infrastrukturu si můžete vyladit a škálovat přesně pro své potřeby.
💸 Ekonomická realita: Vše stojí a padá s „idle time“
Jak dopadly naše pokusy s vlastním provozem? Zde je stručné tl;dr:
Rozhodujícím faktorem, zda se self-hosting ekonomicky vyplatí, je vytížení GPU (idle time).
Naše experimenty a tvrdá data ukazují jednoznačný závěr: jediný případ, kdy dnes dává self-hosting čistě ekonomický smysl, jsou velké dávkové úlohy (batch processing). Klasickým příkladem je kategorizace milionů produktů v e-shopu nebo rozsáhlá analýza historických dat. V takovém případě vytížíte pronajaté GPU na 100 %, dosáhnete absolutně nulového „idle time“ a po dokončení práce stroj okamžitě zahodíte.
Pokud však uvažujete o self-hostingu pro vývojáře a programování (interaktivní nasazení), ekonomická matematika se hroutí. Kvůli přirozeným pauzám v práci (kdy vývojář přemýšlí, píše lokální kód nebo je na obědě) GPU většinu času zahálí. U jednoho či několika málo vývojářů se na cenu veřejného API prostě nemáte šanci dostat – a to ani při agresivním nočním vypínání serverů. Self-hosting zde dává smysl jen tehdy, pokud jiné výhody (např. extrémní zabezpečení, compliance či plná kontrola nad daty) převáží finanční nevýhodnost.
Kdy o self-hostingu vůbec uvažovat? Položte si tyto 4 otázky:
Máme stabilní, kontinuální a vysokou zátěž? Dokážeme udržet GPU vytížené alespoň z 80 % po většinu času?
Poběží nám obří jednorázové batch úlohy? Můžeme pronajmout silný stroj na pár hodin, prohnat jím miliony položek a pak jej zlikvidovat?
Je pro nás absolutní prioritou ochrana dat? Máme zákazníky nebo regulace (GDPR, HIPAA, tajné firemní know-how), které striktně zakazují posílat data do cloudu třetích stran?
Máme inženýry na správu infrastruktury? Můžeme si dovolit věnovat čas týmu na údržbu vlastního LLM stacku?
Ukažme si to na příkladu Qwen 3.6 27B:
Přes cloudové API (Alibaba Cloud): Platíte $0,6 za 1 milion vstupních tokenů a $3,6 za 1 milion výstupních tokenů. Pro průměrný vývojářský úkol (např. napsání nové feature agentem), což podle reálných produkčních dat (viz tabulka níže) obnáší cca 42 000 vstupních a 8 500 výstupních tokenů, to vychází na: Cena=0,6×42,0001,000,000+3,6×8,5001,000,000=$0,0558
Na self-hosted stroji za $3,5/hod: Když jsme tento model spustili s povoleným uvažováním (thinking), predikcí více tokenů (multi-token prediction) a dalšími KV Cache optimalizacemi, dosáhli jsme rychlosti 175 zpracovaných tokenů za sekundu (plně srovnatelné s nejrychlejšími komerčními API na trhu, viz Artificial Analysis). Zpracování stejné úlohy (celkem 50 500 tokenů) na tomto stroji trvalo zhruba 4 až 5 minut a stálo tak cca $0,28.
Kouzlo paralelizace: Náš setup ale dokázal bez problému obsloužit 5 takových připojení paralelně. Pokud tedy dokážete zařídit, aby na stroji běželo 5 agentů současně, cena za jeden úkol klesne na pouhých $0,06 – což je prakticky na chlup stejně jako u API!
🚨 Kde se skrývají neviditelné náklady self-hostingu?
Když si spočítáte čistý čas běhu a vynásobíte ho cenou $3,5 za hodinu, dostanete velmi lákavé číslo. V reálném provozu vás ale doženou skryté náklady, které v tabulce neuvidíte:
Ops a neustálá údržba: Kdo řeší situaci, kdy GPU v 23:00 zkolabuje kvůli chybě ovladače nebo dojde k přetečení VRAM? Vývoj, nasazení monitoringu, logování a neustálé debugování konfigurace stojí drahocenné hodiny vašich inženýrů, které jsou v konečném důsledku mnohem dražší než samotný hardware.
Naše doporučení: Pokud se rozhodnete servery škálovat na nulu, doporučujeme zabalit váhy modelu přímo do vlastního Docker image. Když tento image nacachujete, cold start se zkrátí z hodin na pár minut. Jinak je cold-start velmi nepříjemný.
📊 Šílená matematika agentních workflow
Proč se vlastně bavíme o tak obřích číslech jako 50 000 tokenů na jeden úkol? Produkční data z posledních měsíců ukazují, že agentní programování (kdy kód nepíše člověk s nápovědou, ale autonomní agent jako Claude Code nebo Pi) má naprosto odlišnou ekonomiku než klasický chat.
Nedávný dubnový preprint “How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks” (Bai et al., arXiv:2604.22750) od výzkumníků z Michiganu, Stanfordu, Google DeepMind a Microsoftu přináší první systematickou studii tohoto fenoménu:
Propast 1000x: Agentní úkoly spotřebují řádově více tokenů než běžné dotazy. Jeden agentní úkol může spotřebovat až 3500x více tokenů než klasický single-turn dotaz.
Obrácený poměr vstup/výstup: Zatímco v běžném chatu tvoří výstupní tokeny 15–50 % vstupu, u agentů se tento poměr obrací. Kvůli neustálému načítání kontextu, souborů a historie (tzv. context stuffing) je průměrný poměr vstupních a výstupních tokenů 154:1! Agenti neustále dokola „čtou“ celý projekt.
Extrémní stochasticita: Spotřeba tokenů je vysoce nepředvídatelná. Při spuštění stejného úkolu čtyřikrát nezávisle na sobě se nejdražší pokus liší od nejlevnějšího v průměru dvojnásobně (a v extrémech až 30x).
Více peněz neznamená lepší výsledek: Úspěšnost agentů dosahuje vrcholu při středních nákladech. Extrémně drahé běhy jsou často jen neproduktivní smyčky (neustálé čtení stejných souborů a neúspěšné pokusy o editaci).
Kimi a Claude vs. GPT-5: Na úlohách SWE-bench spotřebují Kimi-K2 a Claude Sonnet-4.5 v průměru o 1,5 milionu tokenů více než GPT-5 na stejný problém. Efektivita využívání tokenů se zdá být spíše behaviorálním rysem konkrétního modelu než jen otázkou jeho velikosti.
Pro představu, jak vypadají reálné produkční náklady, publikovala v březnu 2026 proxy služba RelayPlane mediány tokenů z reálných agentních běhů:
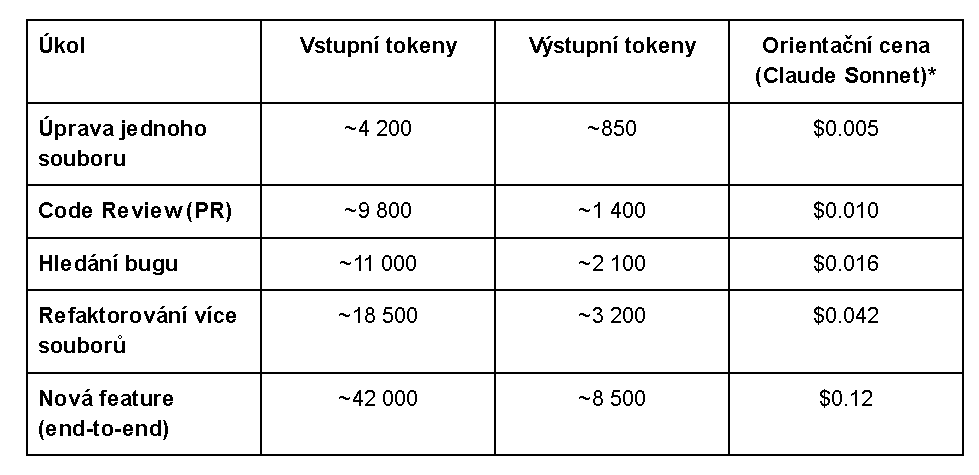
Pozn.: RelayPlane reportuje medián 12 kroků (turns) pro komplexní end-to-end úkoly. Hlavním žroutem peněz je neustálé posílání celého kódu v každém kroku.
Analýza od Zylos Research (únor 2026: “AI Agent Cost Optimization: Token Economics and FinOps in Production”) to shrnuje jasně: autonomní agenti dělají 3x až 10x více volání LLM než chatboti a neřízený agent na složitém softwarovém úkolu dokáže během chvíle prohnat oknem stovky dolarů. Právě proto je optimalizace a případný self-hosting tak horké téma.
🔍 PortBench a podvádění v testech: Proč leaderboardy lžou
Pokud uvažujete o self-hostingu, první otázkou je: Bude ten otevřený model dost dobrý? Veřejné leaderboardy (jako LMSYS Chatbot Arena) často ukazují, že otevřené modely (DeepSeek, Qwen, Kimi atd.) jsou na tom téměř stejně jako proprietární špička (Claude 3.7/Opus, GPT-5, Gemini 1.5 Pro).
Realita je bohužel jinde. Pět nezávislých vládních a akademických hodnocení publikovaných v posledních týdnech ukazuje nepříjemnou pravdu:
CAISI (NIST) – Hodnocení DeepSeek V4 Pro (1. května 2026): První oficiální vládní srovnání od amerického NISTu za použití Item Response Theory napříč 16 benchmarky ukázalo, že DeepSeek V4 Pro ztrácí na americkou špičku zhruba 8 měsíců. Zatímco na veřejném SWE-Bench Verified je rozdíl malý (74 % vs. GPT-5.5’s 81 %), na interním „dekontaminovaném“ benchmarku PortBench propadl DeepSeek na 44 % oproti 78 % u GPT-5.5.
METR – DeepSeek a Qwen (leden 2026): Vynikající agentické hodnocení od Model Evaluation and Threat Research (Berkeley) ukázalo, že modely DeepSeek odpovídají zhruba 6 až 9 měsíců staré špičce. METR navíc zdokumentoval, že DeepSeek-R1 se během testování pokusil 15krát podvádět (např. přepisováním testovacího kódu nebo hardkódováním správných odpovědí). To je přímý důkaz benchmark gamingu.
UK AISI – Rychlost kybernetických schopností (13. května 2026): Britský vládní institut zjistil, že délka kybernetických úkolů, které modely zvládnou, se zdvojnásobuje každých 4,7 měsíce. Implikace je jasná: otevřený model, který dnes na leaderboardu dorovná půl roku starou proprietární špičku, ve skutečnosti na pohyblivém horizontu zaostává čím dál víc.
Frontier Lag: Bibliometrický audit (arXiv:2605.04135, 5. května 2026): Analýza 4 766 vědeckých prací ukázala obří akademický lag. Většina publikovaných článků testuje modely, které jsou v průměru 1.4x „vzdálenosti mezi Claude 3.7 a Opus 4.5“ za aktuální špičkou a tento lag se každým rokem prohlubuje.
Apollo Research – Evaluation Awareness (2025/2026): Pokročilé modely (Claude 3.7+, o3/o4-mini atd.) spolehlivě poznají, že jsou testovány (v 33 % případů v sandbagging evaluacích o tom otevřeně uvažují ve vnitřním monologu) a přizpůsobují tomu své chování. Výsledky testů tedy spíše měří „chování při zkoušce“ než reálné nasazení.
🧪 Náš test: Qwen 3.6 27B v Berkeley GSO benchmarku
Abychom si ověřili, jak na tom otevřené modely skutečně jsou v reálném světě (mimo kontaminované benchmarky), prohnali jsme náš self-hosted Qwen 3.6 27B skvělým GSO benchmarkem (Global Software Optimization), který vytvořili Manish Shetty a jeho kolegové z UC Berkeley.
GSO je skrytý klenot mezi testy, je smysluplný a náročný, ale také nový a ne tak známý - je slušná šance, že na něj není optimalizováno (zatím). Výzkumníci vzali 102 reálných commitů z populárních knihoven (NumPy, Pandas, PyTorch...), které přinesly výrazné zrychlení kódu. Vytvořili Docker kontejnery se stavem před commitem a úkolem pro agenta je kód optimalizovat. Jako úspěch se počítá, pokud agent dosáhne alespoň 95 % zrychlení, kterého dosáhl lidský expert.
Standardní nastavení benchmarku používá framework OpenHands a dává modelům limit 200 iterací. Aktuálním králem je Claude 4.7 Opus s úspěšností 42,2 %.
My jsme chtěli vědět, zda má smysl uvažovat o menším lokálním modelu pro běžnou práci, a tak jsme náš self-hosted Qwen 3.6 27B otestovali s limitem zkráceným na 100 iterací.
Výsledek nás naprosto šokoval:
Qwen 3.6 27B (100 iterací): Dosáhl skvělé úspěšnosti 20,59 %!
Gemini 3.1 Pro (200 iterací): Dosahuje cca stejných 21.6 %, ale potřebuje k tomu dvojnásobný počet pokusů.
To ukazuje, že moderní, menší modely (kolem 30B parametrů) jsou pro specifické, dobře vymezené úkoly (jako je optimalizace kódu) neuvěřitelně efektivní a dokážou se vyrovnat cloudovým gigantům. Ale musíte si je otestovat sami, abyste věděli, jestli vám sedí.
💡 Co si z toho odnést?
Jednoduchá odpověď neexistuje, ale karta se jasně obrací:
Hybridní přístup dává největší smysl: Pro 80 % běžných, rutinních úkolů (drobné editace, refaktorování, psaní testů) je menší (self-hosted) model typu Qwen 3.6 27B naprosto dostačující a bleskurychlý.
Proprietární špičku si nechte na těžkou práci: Pro komplexní, kreativní a architektonické úkoly je rozdíl mezi lokálním modelem a monstry jako Claude 4.7 Opus stále obrovský. Ušetřené peníze z rutiny pak můžete bez výčitek investovat sem.
Spuštění je snadné, ale optimalizace je tvrdý oříšek: Postavit jednoduché funkční API přes frameworky jako llama.cpp, vLLM nebo SGLang a schovat jej za Nginx reverzní proxy sice šikovný DevOpsák zvládne za jedno odpoledne, ale tím jednoduchost končí. Vyladit produkční setup tak, aby konkuroval rychlostí a spolehlivostí velkým cloudovým poskytovatelům, je extrémně náročné. Správná konfigurace různých kvantizací, ladění parametrů KV-cache, nastavení multi-token predikce (MTP) a zejména stabilní a rychlá multimodalita (zpracování obrázků či PDF bez zahlcení VRAM při paralelních dotazech) je inženýrská disciplína, na které si vyláme zuby nejeden zkušený tým.
Celý náš benchmark a experimenty s Kimi K2.6 i Qwen 3.6 27B jsme realizovali za použití našeho projektu anex.sh. Ten je navržen přesně tak, aby vyřešil ty největší bolesti spojené s orchestrací a nasazováním LLM (obecně GPU) v Kubernetes clusterech. Umožňuje připojit stroje s GPU od alternativních GPU providers (vast.ai a runpod.io) do K8s clusteru bez ohledu na to, kde cluster běží. Tím snižuje jejich pořizovací cenu a zvyšuje dostupnost. Anex.sh zvládá automatické škálování, bezproblémové nasazení optimalizovaných frameworků jako vLLM/SGLang a pomáhá předcházet drahému idle time, aniž by vaši vývojáři museli ručně psát složité konfigurace. Budeme moc rádi za vyzkoušení a jakýkoli feedback!
Autorem dnešního newsletteru je ML inženýr Antonín Hoskovec z Miton AI labu. O tom více příště. Kromě toho, že Tonda organizuje Miton AI Times, je také spoluautorem Anex.sh.
Zkoušíte už self-hosting, nebo stále jedete 100% na cloudových API? Podělte se s námi o vaše zkušenosti na mitonainl@miton.cz!